
In the world of finance, data is the lifeblood of informed decision-making. Whether it’s analyzing market trends, evaluating investment opportunities, or conducting research, having access to accurate and up-to-date financial information is essential. Web scraping, the process of extracting data from websites, has emerged as a valuable tool for gathering financial data from various online sources. The article will explore ideas behind financial data scraping with Python.
With a plethora of web scraping tools available, the choice often depends on your programming expertise and the complexity of the scraping task. Popular Python libraries like Beautiful Soup, Scrapy, and Selenium offer varying levels of abstraction and functionality. Beautiful Soup provides a simple interface for parsing HTML documents, while Scrapy is designed for large-scale scraping projects. Selenium, on the other hand, can handle dynamic content and JavaScript-rendered pages.
Quick jump:
The Target Data
The first step in web scraping is to define the specific financial data you need. This could include stock prices, company financials, economic indicators, or other relevant information. Clearly defining your data requirements will help you narrow your search and focus on websites that contain the relevant information.
Then identify the websites or online sources that contain the financial data you need. This may involve searching for financial websites, company websites, or government databases. Popular sources include Yahoo Finance, Google Finance, and the U.S. Securities and Exchange Commission (SEC) Edgar database.
Choosing a Scraping Tool
With a plethora of web scraping tools available, the choice often depends on your programming expertise and the complexity of the scraping task. Popular Python libraries like Beautiful Soup, Scrapy, and Selenium offer varying levels of abstraction and functionality. Beautiful Soup provides a simple interface for parsing HTML documents, while Scrapy is designed for large-scale scraping projects. Selenium, on the other hand, can handle dynamic content and JavaScript-rendered pages.
Analyzing the Website Structure
Before diving into the code, it’s essential to understand the website’s HTML structure. Inspecting the HTML code will reveal how the data is organized and presented. This will help you identify the specific HTML elements that contain the target data. Look for patterns and consistent structures that can be used to extract the data efficiently.
You could use the building features of the Chrome browser to check the HTML structure and path to the necessary object. To access the tool you need to right-click on the object and select the ‘Inspect’ menu option.
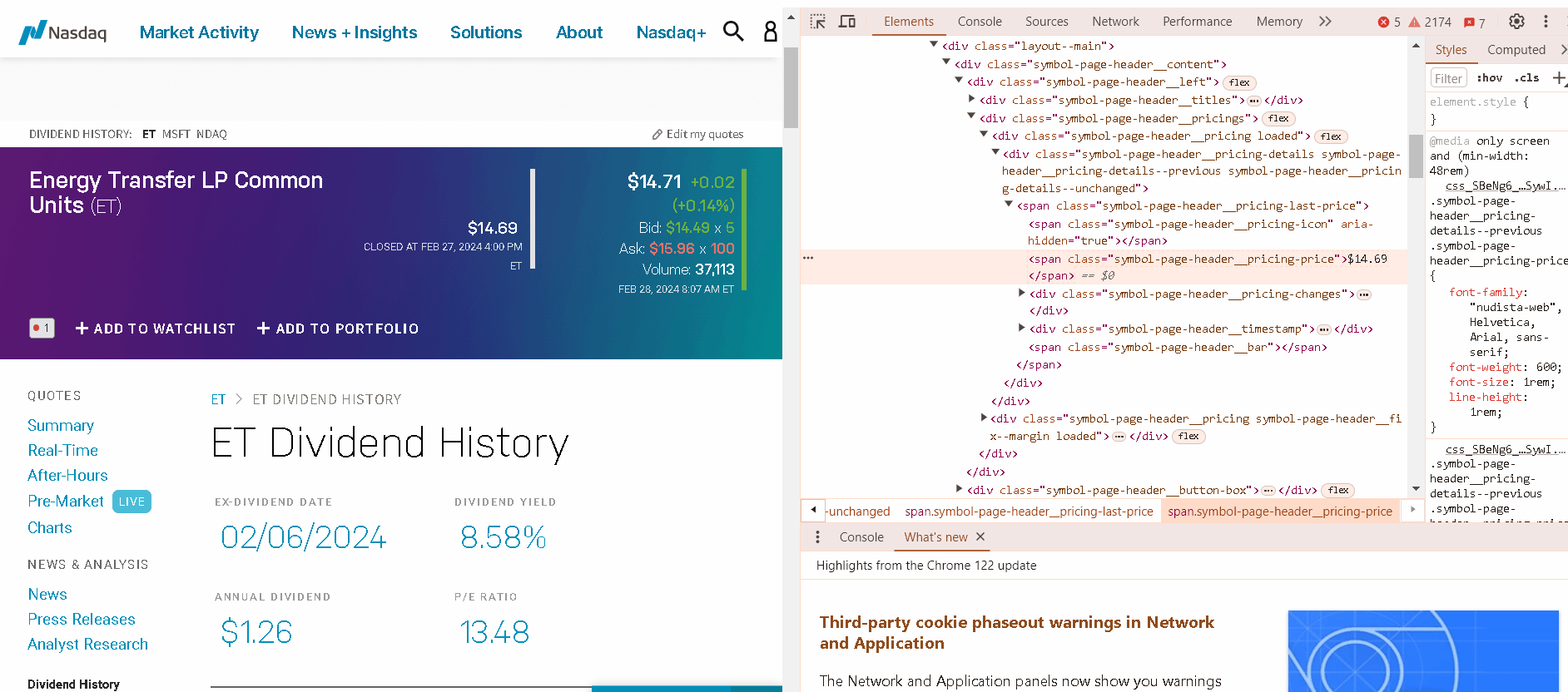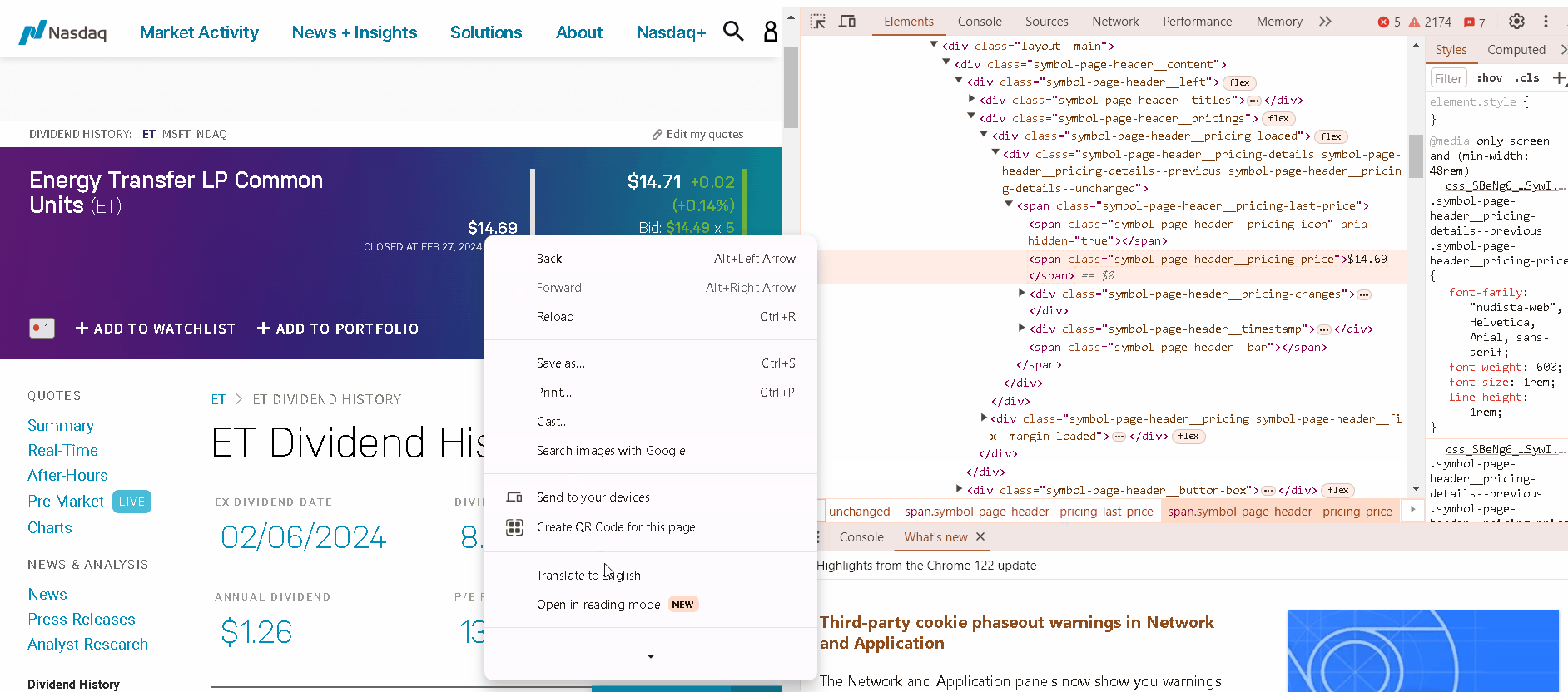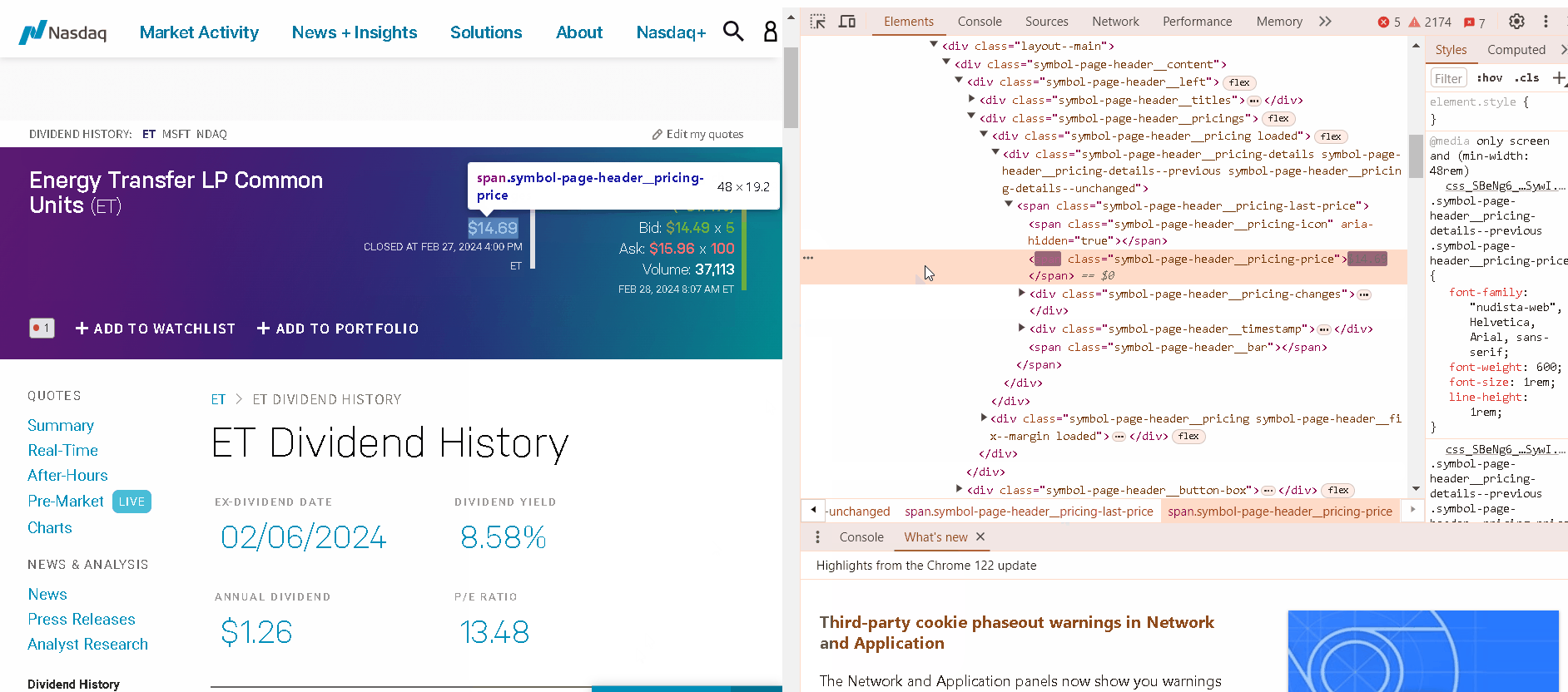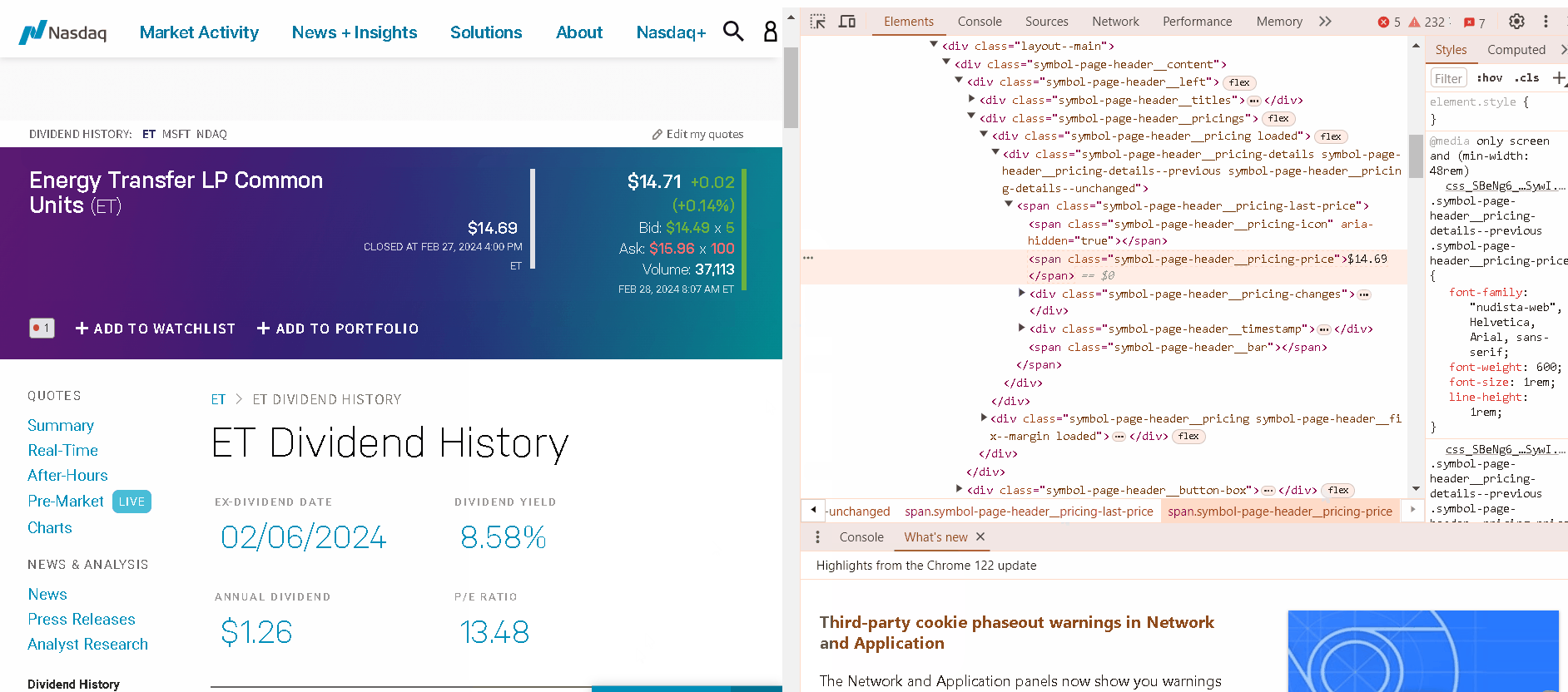
Scraping Static Pages With BeautifulSoup
With the target data and website structure in mind, it’s time to write the scraping script. You’ll need to write code to extract the desired financial data. This code will typically involve making HTTP requests to the target URLs, parsing the HTML responses, and extracting the relevant data using appropriate selectors or patterns.
Here is an example of Market capitalization from Yahoo Finance:
import requests
from bs4 import BeautifulSoup
def get_market_cap(symbol):
url = f"https://finance.yahoo.com/quote/{symbol}"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
# Find the element containing the market capitalization
market_cap_element = soup.find("td", {"data-test": "MARKET_CAP-value"})
if market_cap_element:
market_cap = market_cap_element.text
return market_cap
else:
return "Market capitalization not found"
else:
return "Failed to retrieve data"
# Example usage
symbol = "ET"
market_cap = get_market_cap(symbol)
print(f"Market capitalization of {symbol}: {market_cap}")
For the code to run properly, you need to install the ‘requests’ and ‘BeautifulSoup’ packages. Please run the following command in your terminal: ‘pip install BeautifulSoup, requests’
Selenium for Handling Dynamic Content
If the website uses JavaScript to dynamically load data, you may need to employ a headless browser like Selenium. Selenium can render the page and access the data before it disappears, effectively overcoming dynamic content challenges.
An example of the Python code to get data from NASDAQ you will find here:
# Import necessary libraries
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up WebDriver (ensure the WebDriver is in your system PATH or provide the path)
driver = webdriver.Chrome()
# Navigate to the webpage you want to scrape
driver.get("https://www.nasdaq.com/market-activity/stocks/msft")
# Define a function to scrape stock data
def scrape_stock_data():
try:
# Wait for the element to be visible (adjust the timeout as needed)
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, ".symbol-page-header__pricing-price"))
)
# Once the element is visible, extract the data
stock_price = element.text
return stock_price
except Exception as e:
print(e)
finally:
# Make sure to close the WebDriver session
driver.quit()
# Call the function to scrape stock data
stock_price = scrape_stock_data()
print("Stock Price:", stock_price)
For the code to run, you need to install the Selenium package, and run it in the terminal: ‘pip install selenium’.
Also, make sure that you have the relevant Chrome driver installed and set the correct PATH variable for the driver. The code example looks for the pricing data of Microsoft, you can modify the code to look for other tickers.
Storing and Organizing the Data
Once the data has been extracted, it needs to be stored and organized in a suitable format. Common options include CSV files, JSON files, or databases. Depending on the volume and complexity of the data, you may need to implement data cleaning and organization techniques to ensure the quality and usability of the data.
Respecting Robots.txt and Terms of Service
Before scraping any website, it’s crucial to check for a robots.txt file. This file specifies restrictions on scraping, and adhering to these guidelines is essential for respecting the website’s rights. Additionally, always review and comply with the website’s terms of service to avoid scraping data in a way that could overload their servers or violate their policies.
You can manually check for the file using the browser’s address bar, and type the URL of the website followed by “/robots.txt”. An example for Yandex Finance:
https://finance.yahoo.com/robots.txt
EODHD Financial API Provider
While web scraping can be a powerful tool for extracting financial data, it’s also worth considering EODHD financial APIs. Our service offers access to a vast range of financial data, through well-documented and structured APIs.
Financial APIs offer several advantages over web scraping. We provide access to a wider range of data sources, including historical and real-time data. Additionally, APIs are more reliable and consistent than scraping, as the data provider maintains them. Moreover, using APIs eliminates the need to deal with website changes and potential copyright issues.
We highly recommend checking out the EODHD Python Financial Library, which comes with ready-to-use examples for data retrieval. This can significantly streamline your process of acquiring financial data and integrating it into your projects.
Whether you choose to use web scraping or financial APIs, it’s important to be mindful of data usage and respect the rights of data owners. By following ethical practices and adhering to data usage guidelines, you can responsibly harness the power of data to make informed financial decisions.
Feel free to contact our amazing support to ask for the current discounts, we would be more than happy to assist and guide you through the process.